My research is primarily in natural language processing and human-AI interaction, with a particular focus on artificial intelligence as a knowledge tool. Some ongoing interests are:
- Social impacts of AI-mediated information access
- Algorithms and interfaces for social and scholarly sensemaking
- Novel methods in computational social science & science of science
- Bridging knowledge & culture gaps
- Democratizing access to AI
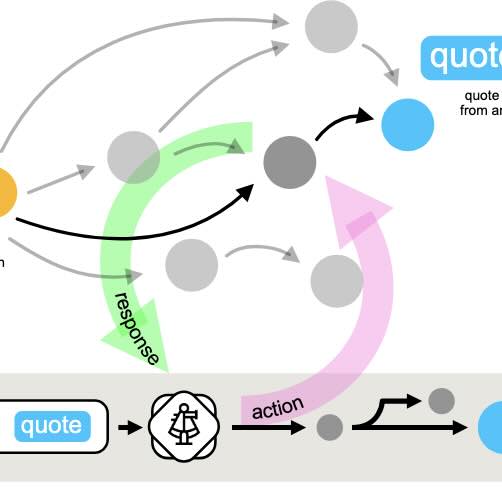
We introduce the task of knowledge navigation, challenging LLM agents to explore a scholarly corpus to find information. Turns out even the top models have a hard time.

Through conversations with practitioners in law, policy, and science, we explore the gap between domain expert needs and current NLP research goals.

A large effort to write challenging questions that fool SOTA LLMs (circa 2024). My contributions focused on law, perception, and model induction via cellular automata. Happy to discuss this project, especially how to think rigorously (and when to be skeptical) about some of the claims made based on it.
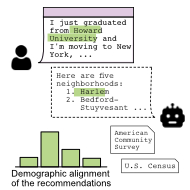
We show that large language models produce racially biased responses based on implicitly revealed information about users' identity, and that when questioned in further conversational turns, model responses obfuscate the effect.
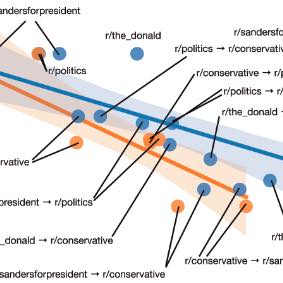
Comparing language models trained on distinct communities can reveal echo chambers, and key points of linguistic divergence.

A novel interface to explore consensus and conflict in document clusters, powered by an automatic fact verification system for scalable pairwise NLI.
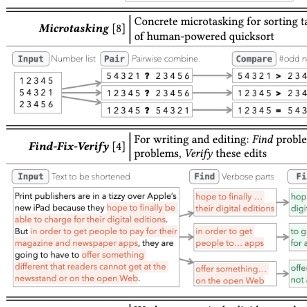
Chain of thought isn't the only framework – we explored LLMs as components of crowdsourcing pipelines.
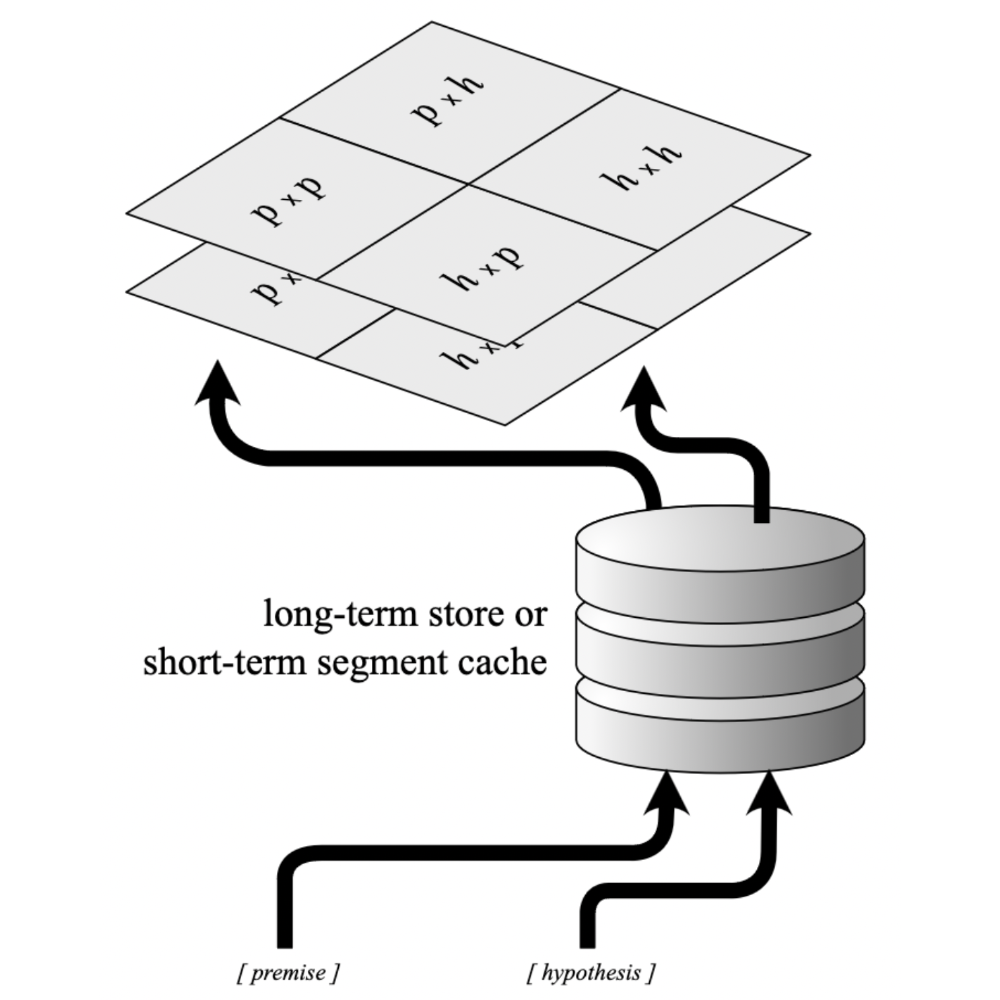
We introduce an attention masking strategy to partially parallelize computation for multi-segment reasoning tasks, showing that simple structural changes in the network can dramatically increase computation efficiency without harming performance.
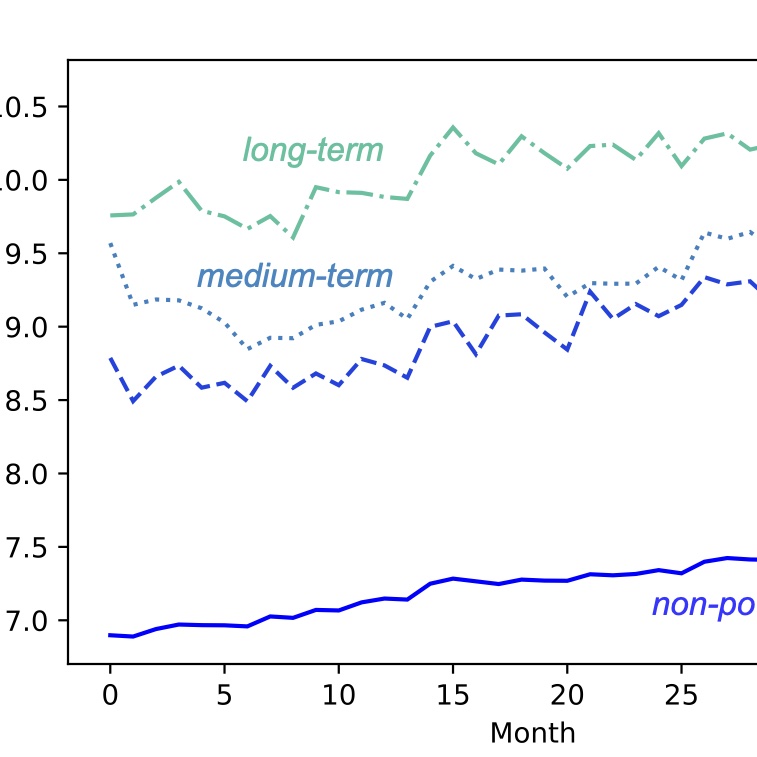
We performed a computational study of the social trajectory of "power users" on Reddit, studying their trajectory across communities and characterizing the content they write, observing a correlation between a user's rise to power and increasingly divisive content.
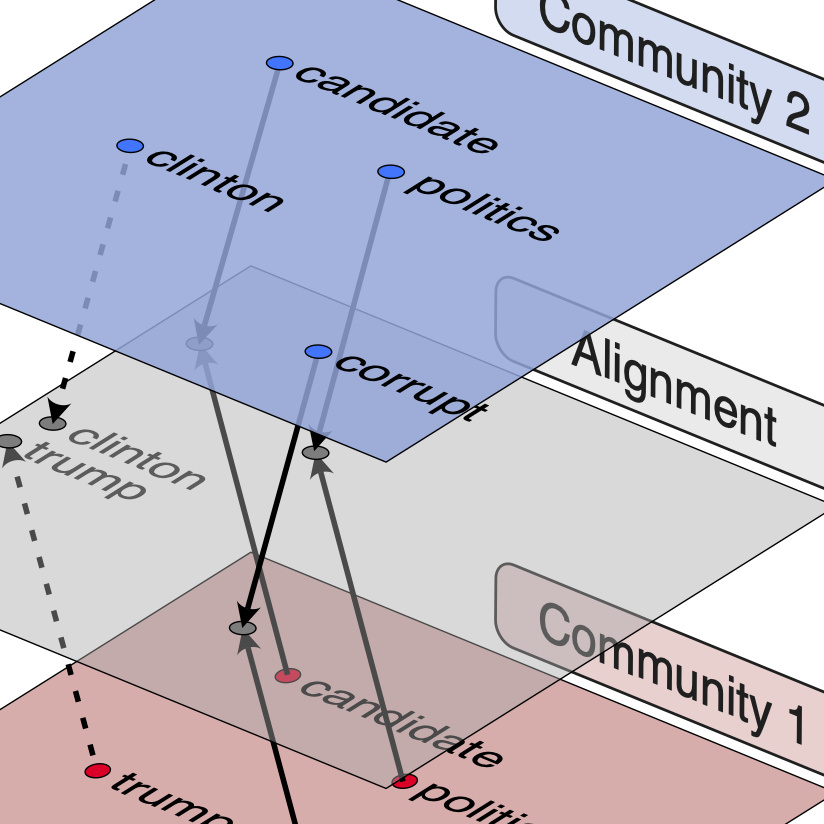
We align unsupervised word embeddings to automatically discover polarized word meanings across communities, find unexpected conceptual homomorphisms, and enable future studies of ideological and worldview differences in text.

Using methods from link analysis, we identify the most influential and powerful users on Reddit.
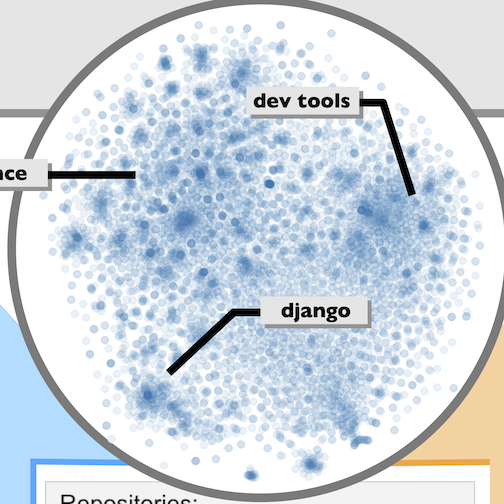
Using data from over 28M Github repositories, we train and evaluate repository representation vectors based on social, semantic, and structural features in the codebases.


I assisted with research on privacy and EdTech, managed the Center's "This Week in Student Privacy" newsletter (complete with weekly cat pictures), and advised the MIT Media Lab's Lifelong Kindergarten team on communicating the remix philosophy :)
In memoriam
Here lie some of the unfinished (but interesting) or unpublished projects of yore.
We developed a technique for sentence-level reranking and filtering of evidence passages, based on a signal of which sentences provide sufficient information to the FiD reader model. Ultimately RECOMP arrived at the same algorithm, applied to LLM RAG.